云计算中的资源调度
云厂商将机房中服务器的计算能力进行整合,如 CPU、内存等,并把这些硬件统一抽象为资源,然后按需卖给用户,这就是云计算理念,怎么把这些资源有效的管理和调度起来,最大化资源利用率,关系着云厂商的成本和营收,也是各厂商实现差异化的一个重要切入点。本文讲讲云计算中的资源调度,或者称为 scheduler。
openstack 中,有个叫做 nova-scheduler 的模块,类似于 k8s 中的 scheduler 组件,这两个模块就是资源调度,功能类似,是我们讨论的主角。要说明的是,本文并不打算拿源码逐行分析,而只是阐述资源调度里的一些核心思想。
什么是资源调度
资源调度要解决的核心问题是,用户创建的 VM 或 pod 应该分配到集群的哪个节点上。以及当某个节点负载超过报警阈值时,自动将 VM 或 pod 调度到其他负载较低的节点,以达到整个集群中所有节点的 CPU,内存,I/O 等指标保持大致相当的水平,类似于负载均衡。毫无疑问,这样做一方面提高集群的资源利用率,另一方面降低个别节点负载过高导致 VM 或 pod 性能跟着受影响。为了方便,下文只用 VM 代表被调度对象。
怎么做资源调度
资源调度的过程就是一个筛选最优解的过程,这里的解指的是集群中最优的节点。为了找到最优解,显然需要知道节点有哪些过滤条件,影响因子,以及各影响因子的权重。只要找到这些因素,我们就可以对各节点进行过滤筛选和打分排序,直到找出最优节点,筛选过程类似于下图。
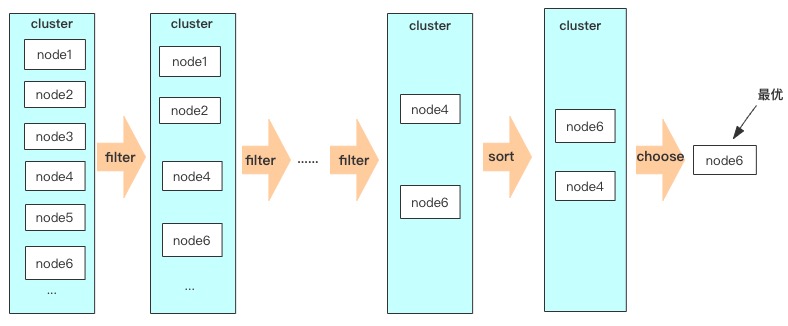
一般的,资源调度对节点的筛选会分为两个步骤:硬性条件筛选,软性条件筛选(需要说明下,这两个名词是我参考了文末的资料,并非原创)。在一些开源框架中,这两个步骤都有特定的叫法,如 openstack 中,这两个步骤分别称为 filter 和 weighting,在 k8s 中,分别称为 predicate 和 priority。
硬性条件筛选
硬性条件筛选,解决的是”能不能“的问题,即这个 VM 能不能建在这个节点上。那么有哪些硬性筛选条件呢?
-
节点类型 节点类型包括节点的固有属性,包括硬件类型,软件类型等。比如用户创建的 VM 对计算性能有要求,指定了 CPU 型号为 1802,因此那些 CPU 非指定型号的节点将直接被过滤掉;再比如,某个节点当前被设置为 disable 或 maintanced,表示该节点有问题或处于维护状态,这样的节点将被过滤掉。
-
计算容量 整个很好理解,只有容量满足需求的节点才能通过筛选。比如用户创建的 VM 是 8 核 16 G,那么那些可用 CPU 数少于 8 或者可用内存少于 16 G 的节点将被过滤掉。
-
磁盘容量 这个类似于计算容量,用户需要一个 500 G 的本地 SSD 磁盘,那些磁盘容量少于 500 G 的节点将被过滤掉。
-
节点配额 当一个节点计算容量和磁盘容量都满足条件,并不一定能通过筛选,还要看该节点是否满足系统配额,比如系统规定,每个节点最多只能放有 10 个 VM,那么如果某节点已经到上限,此时也会被过滤掉。
这里列举的只是一部分典型的筛选条件,还有其他的条件这里没有给出。
硬性条件筛选过滤掉了所有不满足条件的节点,剩下的节点都是满足创建 VM 的。硬性条件筛选不具有权重,筛选时,根据某一条件,节点要么能通过筛选,要么不能。任意一个条件筛选完后,发现没有可用的节点,那么就认为调度失败,要么直接返回错误,要么循环一直重新筛选,直到筛到有可用节点为止。 只有通过所有条件筛选的节点,才可以进行下一步软性条件筛选。
软性条件筛选
通过上一步的硬性条件筛选,现在可以对剩下的所有节点进行软性条件筛选了。软性条件筛选解决的是”好不好“的问题,即 VM 建在这个节点上好不好,是不是最优的。我们也看下有哪些软性条件。
-
资源占用小 这个原则很直观:VM 最好是建在那些负载较低的节点上,这样有利于 VM 的快速启动以及性能。负载较高的节点,会导致上面的 VM 资源争抢严重。最坏的情况下,甚至导致节点宕机,因此最好不要选择负载高的节点。
-
亲和性 亲和性是说,尽量将多个 VM 放在一个节点,或者绑定在一个节点上。例如,现在每个节点上有 500G 的磁盘空间供 VM 使用,假如 VM A 占用了 Node1 上的 300G,这时有一个创建 VM 的请求,它想要 200G 的空间,那么它可以选择节点 Node1,也可以选择其他 500G 的节点,但根据亲和性原则,它最好选择 Node1,因为这样正好可以把 Node1 上的磁盘用完,充分利用了磁盘资源。如果不这样选择,而是选择了其他有 500G 容量的节点,如 Node2,那么现在 Node1 上剩 200G,Node2 上剩 300G,如果这时再想创建一个 400G 或 500G 的 VM,Node1 和 Node2 均无法满足磁盘容量需求,这时不得不选择一个其他有 500G 的节点,如 Node3。这时 Node1 和 Node2 上剩余的磁盘资源就这么空着浪费掉了,有了亲和性,只需要使用 Node1 和 Node2 即可,这就是一个亲和性表现。
-
打散分布 打散正好跟亲和性相反,也可以称为反亲和性。有的情况下,我们会按照某种规则,将资源尽量进行打散分布,例如,某个用户创建 5 台 VM,这里就可以将这 5 个 VM 做打散处理,将他的 VM 尽量分布在不同的节点上。这样的好处是,避免了某个节点宕机导致该用户在上面建的 VM 全挂,通俗点,不要将鸡蛋放在一个篮子里。这里是按照用户来进行打散筛选的,实际还有很多其他维度可以应用打散筛选规则,如根据标签打散,在创建 VM 时,给 VM 打上一个标签,有相同标签的多个 VM 打散分布在不同的节点上。
-
本地基础镜像缓存 本地基础镜像是指 VM 运行时需要的 base 镜像。我们知道,KVM 使用了一种称为写时复制的技术,每个 VM 都是由一个 base 层和一个 top 层构成,base 层是只读的,里面的数据是操作系统,和一些预装程序,所有的写操作都在 top 层完成,这样的好处是,多个 VM 可以共用一个 base,而只有 top 层独立。base 一般称为基础镜像,也可以叫 backing file。这些基础镜像一般会集中放在一个镜像服务器上,当需要时,会被下载到指定节点,作为这个节点上所有相同系统的 VM 的 base。后面如果再创建了相同系统的 VM,就不用再去下载了,这样可以大大加快创建 VM 的速度。 现在假如要创建一个 CentOS7 的 VM,Node1 上已经有 CentOS7 的 base,而 Node2 上没有,那么我们应该选择 Node1,这样免去了下载 base 的时间成本。
软性条件筛选每个因素都可以有对应的权重,根据这些权重和分值,可以给通过了硬性条件筛选的所有节点计算加权分值,得分最高的节点即是最优节点。
最优节点找到后,调度的任务就完成了,剩下的就是在这节点上创建 VM 了。k8s 中,这个过程被称为 binding(pod 和 node 绑定)。
上面列出的只是一部分条件,其他的条件不一一列举,事实上,软性条件筛选灵活性很高,比硬性条件筛选更复杂,更主观,影响因子可以有很多,权重也可以动态调整,需要根据实际情况,业务情况,选择合适的条件,合理的权重。
总结下来,整个调度过程,就是一个不断过滤筛选的过程,输入 VM 的各项规格,调度器根据这些规格参数,以及集群中所有节点的属性,输出一个最合适的节点,可用下图来概括调度的作用。
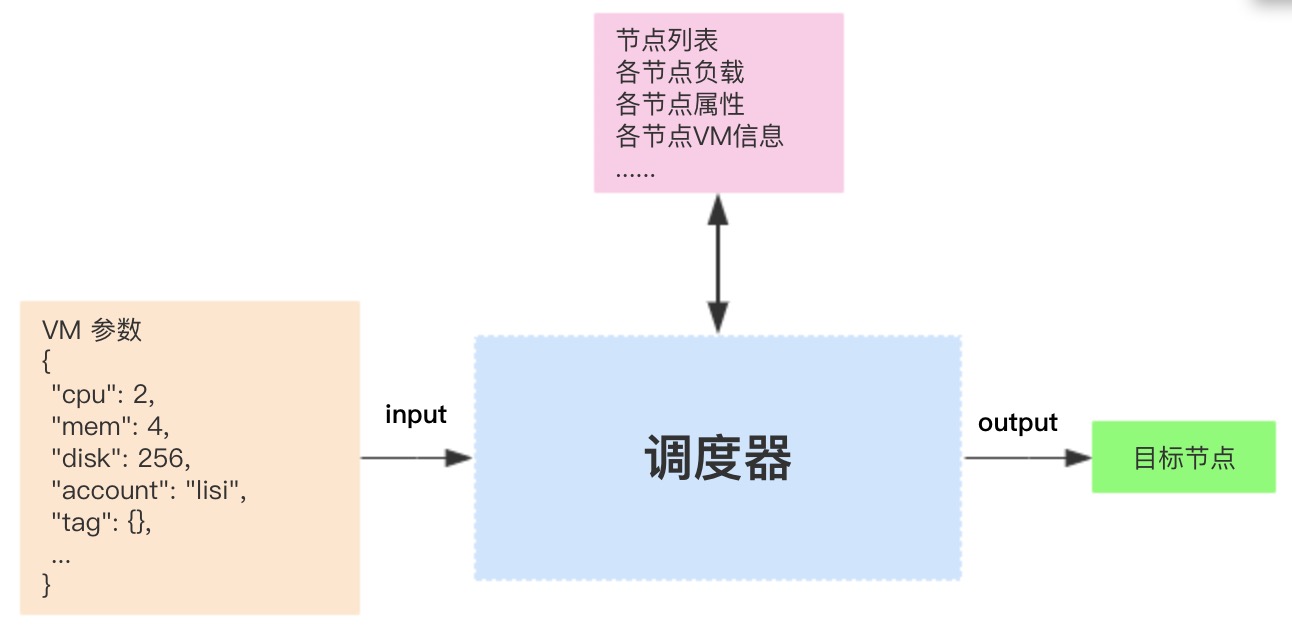
另外,上面的每个筛选流程都是独立的,也就是说,可以在任意两个流程中插入自己的筛选逻辑,只要符合期望即可,甚至完全不用框架提供的调度器,完全使用自定义的调度器。事实上很多企业内部自研的调度,都是在开源框架的基础上,加入了一些定制化的调度逻辑来满足自己的需求,比如,在硬性条件筛选阶段,把过滤效率高的流程提前,一次性过滤尽可能多的不符合条件的节点;软性条件筛选阶段,在允许一定容忍度情况下,寻找一个局部最优节点而不是全局最优节点,也能加快筛选过程。但也需要考虑到,筛选逻辑并非越多越好,过多反而会使筛选效率降低,得不偿失。
资源重调度
经过上面的步骤,我们解决了如何为新创建的 VM 分配一个合理的节点。但需要注意,系统运行过程中,节点的各参数都是动态变化的,比如某节点现在负载较低,过了一会儿,该节点上面的 VM 做大量运算,或者节点执行像打快照这类比较重的操作,导致节点负载升高,超过警戒阈值,那么这时需要对节点上的 VM 做迁移操作,将部分 VM 迁到其他节点,以降低该节点的负载。迁到哪个节点上呢?这就又涉及到上面的调度过程了,还是需要经过硬性条件和软性条件筛选,这个过程就是重调度。
资源重调度是一个很重要,也很复杂的问题,最原始的方式是人肉盯监控报警,一旦出现负载高的节点,由人工手动迁移 VM,这种处理方式简单但费力,半夜被报警吵醒也是常事,相当于响应式处理。当集群节点数上去后,就需要一种能自动迁移的机制了,也就是智能调度,这种方式不仅免去人工操作的繁琐,还具有一定的预测能力,即依靠机器学习或神经网络等技术,能提前预知哪些节点可能会报警,那么就提前自动迁移该节点上的 VM,整个过程不需要人工干预。
总结
云计算完成了 CPU、内存、磁盘、网络等资源的抽象,资源调度解决的问题是如何将一个 VM,一个 pod,或者更抽象点说,一个应用,放到最合适的位置,以提高整个集群中节点的使用率,既不出现节点负载很高导致性能受影响,也不会有使用率低导致机器的浪费。本文简单介绍了资源调度的流程,包括硬性筛选和软性筛选,以及一些典型的筛选条件,实际使用的调度要比这复杂的多,基于此,智能调度也是未来资源调度领域的一个热点。
参考
https://tech.meituan.com/2019/08/22/kubernetes-cluster-management-practice.html 《容器与容器云》
- 原文作者:JimmyXu
- 原文链接:http://xujimmy.com/2019/08/11/schedule-in-cloud.html
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。